Data Lessons from 2021
by Uday Kumar, Chief Digital Officer
January 3, 2022
Data Lessons from 2021
 Right after the Thanksgiving break, I attended my very first AWS ReInvent event. Although I had seen videos and photos of prior ReInvents, I was only able to internalize its sheer size and scale when I attended it in person! It was a sea of energetic participants and an infinite list of informative breakout sessions! As a digital guy, my goal is to bring data and technologies together to design meaningful enterprise solutions and deliver compelling consumer outcomes. Those 4 days at ReInvent 2021 reinforced my belief that the world has barely begun scratching the “data” surface and that conquering the data frontier is a journey, not a destination.
Right after the Thanksgiving break, I attended my very first AWS ReInvent event. Although I had seen videos and photos of prior ReInvents, I was only able to internalize its sheer size and scale when I attended it in person! It was a sea of energetic participants and an infinite list of informative breakout sessions! As a digital guy, my goal is to bring data and technologies together to design meaningful enterprise solutions and deliver compelling consumer outcomes. Those 4 days at ReInvent 2021 reinforced my belief that the world has barely begun scratching the “data” surface and that conquering the data frontier is a journey, not a destination.
A data-driven organization is imperative for the future.
Having spent some years running a card platform org at Capital One and now getting a start in the federal space (just a few months in), I want to share a few things I have observed, experienced, and learned (often the hard way) around the topic of data and technologies over the last year. I hope some of these are relatable and that you find them useful towards either rounding your understanding or applying to an ongoing/upcoming project. Of course, I’d love to read your thoughts in the comments section of this article.
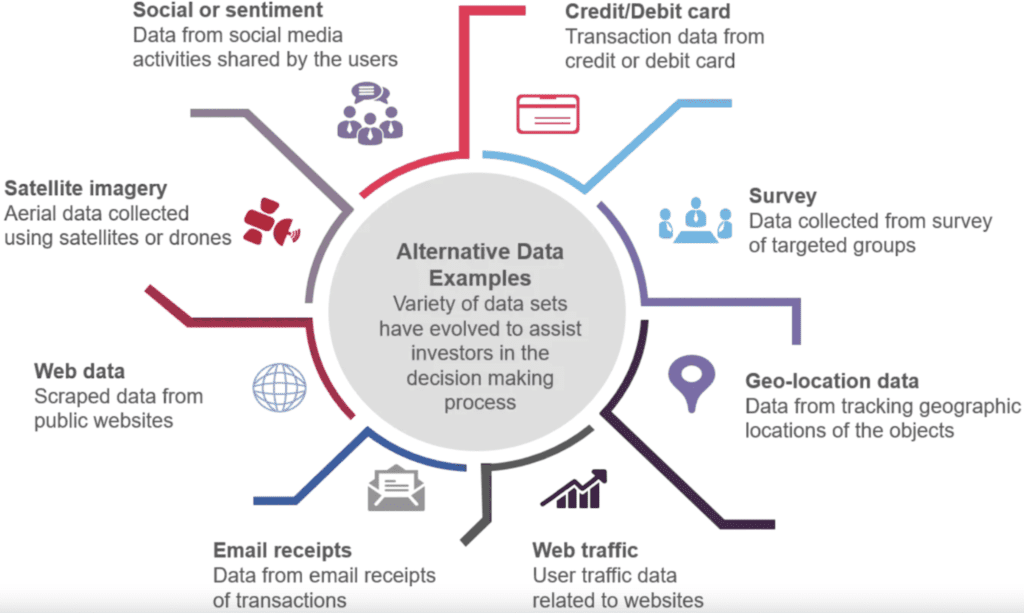
1. Your data is just not good enough. COVID-19 put the whole economy on its head and challenged all kinds of proven, conventional wisdom. Businesses and consumers found new ways to do or not do work, making or not making money. So the typical data that you relied on for credit underwriting or fraud detection (from the likes of credit reporting agencies and payment processors) is just not adequate or trustworthy enough. Customers self-reported data is equally suspect. You have to partner-with/procure alternative data sources (ADS) like geolocation (foot traffic), website usage, satellite images, and IP addresses, and augment your business processing rules to be able to make smarter decisions. This typically requires third party licensing agreements, working with data aggregators.
2. Make data quality a forethought, not an afterthought. A lesson that I learned the hard way is that data quality must be part of your solution design and not something that you measure/correct after-the-fact. Often teams focus simply on the latter and create fancy dashboards (using Tableau, Databricks) that look at the exhaust of the application systems for data distress/error signals. The problem with this approach is that its already too late! The transaction has already completed, the data has already propagated to downstream systems, customers are already escalating the issue, the potential damage already done, and now you are applying precious resources to troubleshoot, triage, resolve the data defects. Consider building logic and intelligence within the system itself that looks for data anomalies, aberrations, and inconsistencies in real-time and takes the corrective action before the data is consumed and persisted. Yes, you may not hit the mark 100% of the time but you will make a huge positive dent in your customer outcomes and production support utilization. A product like AWS Deequ can help here.
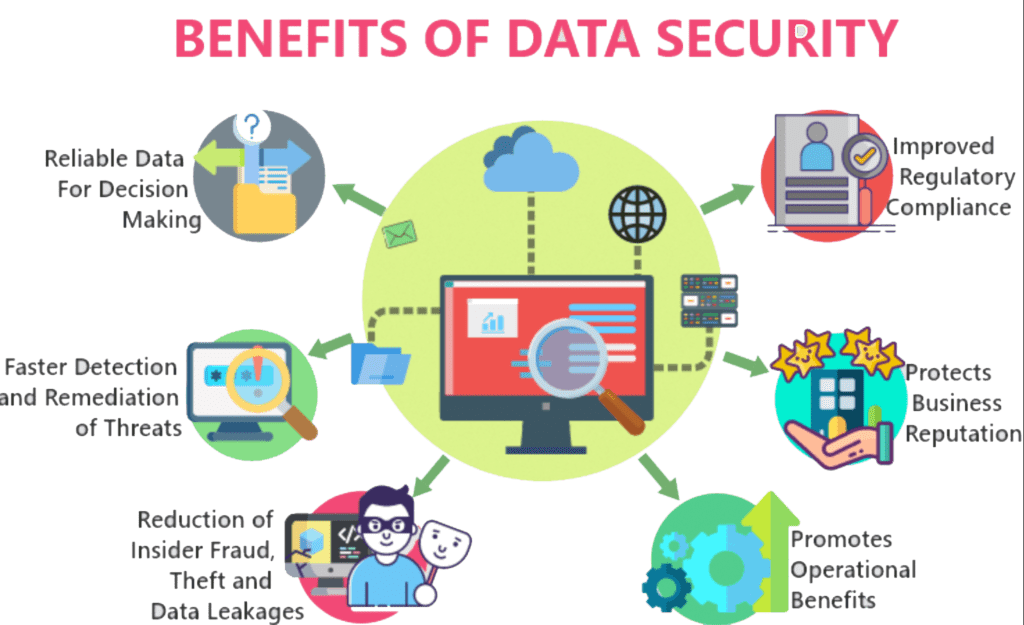
3. Regardless of its origin, you own your data security. Often times, the data coming your way is coming from a trusted partner and is part of a larger payload. But there is a good possibility that your organization’s data governance policies are more stringent (Ex: SS # cannot be in clear text) when it comes to data privacy and protection. So if you were not expecting a social security number but somehow it (or something like it) is showing up in security scans in an address field, it is your responsibility to protect/mask it. Why? Because it is now sitting in your datastore. There are a few different ways these scenarios can be handled (one-time and systematically), but the point is that it is your responsibility now to protect it. Furthermore, data polices typically apply to all instances of your environment, not just production.
4. Follow your data, all the way to the end. Its crazy how many times I have seen people consume and process data, and then just “throw it over the fence” without caring for or considering downstream processes. I know it, I used to be one of those ignorant people. You may have declared victory for your work but you have created potential tech debt for some team (could be yours too) that may come back and haunt you later. That data your team is producing is being streamed and possibly transformed for operational (i.e. data lake) and analytical (i.e data warehouse) data stores. These downstream processes and locations have product and tech owners. The right approach is to make time upfront with your downstream partners to understand their standards, processes, technologies, and KPIs in order to design your use case thoughtfully and responsibly. Go a step further and include the downstream in testing and validation of data streaming use cases. You don’t want a downstream owner showing your platform as the one being the source for non-compliance or the root-cause for a breakdown. BTW, you can check out products like Delta Lake and Snowflake for your operational and analytical data store needs.
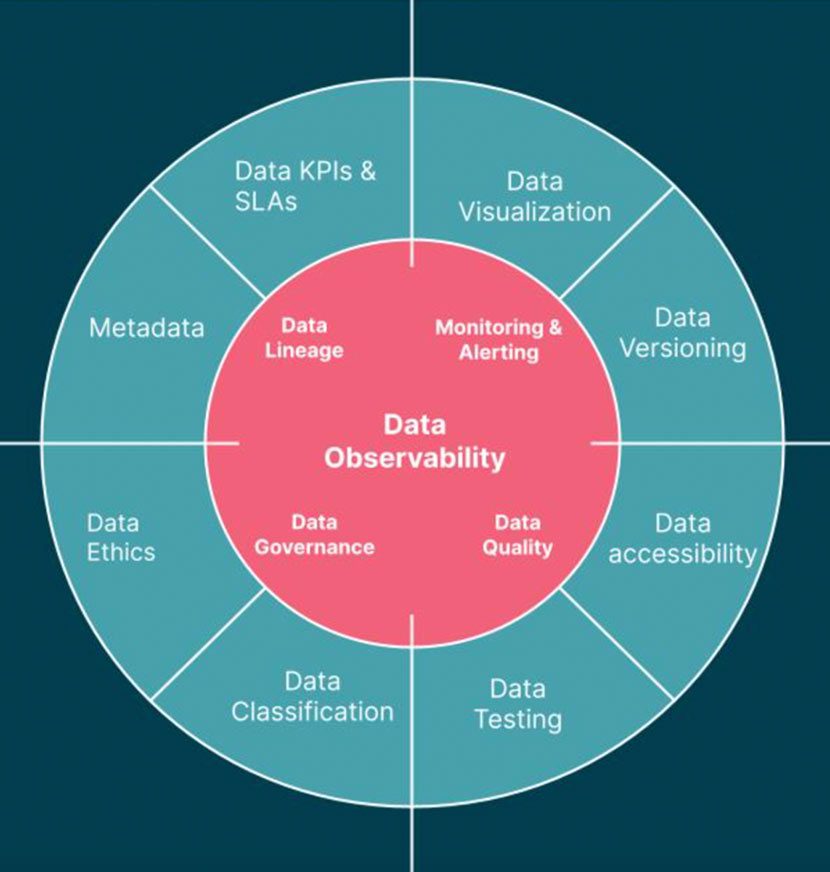
5. Build data observability. We continue to be busy gathering seemingly endless streams of data from a growing number of sources and amassing an ecosystem of data storage, pipelines, and would-be end users. With every additional layer of complexity, opportunities for data downtime — moments when data is partial, erroneous, missing, or otherwise inaccurate — multiply. My teams and partners spent numerous hours chasing and resolving data issues, and by some industry estimates, teams spend ~40% of their time here. The way to tackle this inefficiency is to start applying DevOps best practices to your data pipelines and processes. You need to start investing in tooling, developing data-specific SLAs, and delivering on the high level of data health. In other words, you must invest in the area of “data observability”: Maintaining a constant pulse of the health of your data systems by monitoring, tracking, and troubleshooting incidents to reduce, and eventually prevent, downtime. My teams have used tools like Splunk, Datadog, and PagerDuty to move the need on observability.
A data-driven organization is imperative for the future.
6. Lots of people are interested in your data. You might think that the data your systems are exhausting is only for specific downstream system use cases or a team of business analysts or some compliance team, but think again. Once your data has made it to the authoritative operational or analytical data stores, it is now available to a variety of other consumers like the operations risk, data science, or fraud teams. These stakeholders might not show up on Day 0 or Day 1 or you might have considered and dismissed them based on some assumptions. However, it is always a good idea to give them a seat on the table, bring them into the conversation early on, and collectively make the call to include or exclude their needs and use cases. Declaring and socializing your data processing and streaming intents early, often, and to a wider audience is best practice I would encourage you bring to your teams and organization.
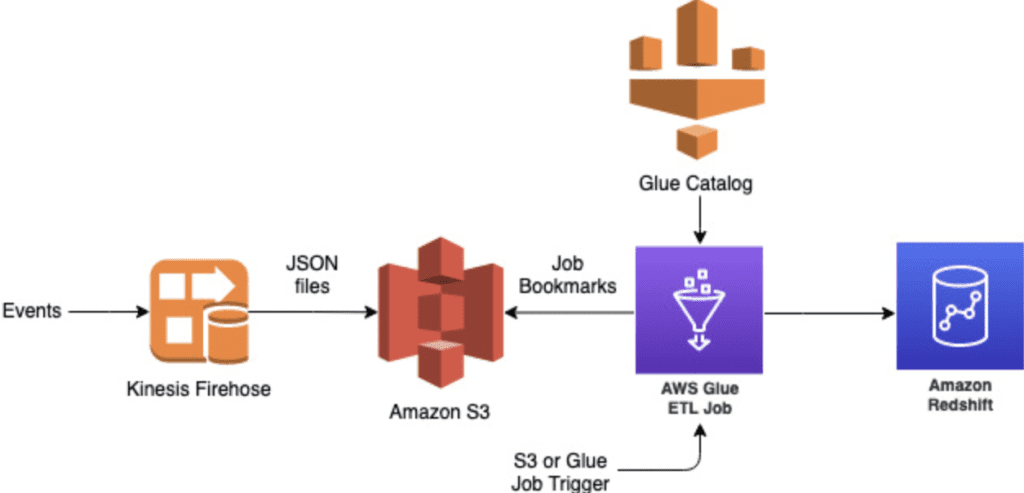
7. Your customers need data NOW. Those internal customers and stakeholders sure are restless when it comes to their data needs. I don’t blame them; they are at the forefront of the money making/saving intents, be it launching new credit products, building new underwriting models, or improving existing fraud models. The Data Science team may have been working on a new model in their sandbox which they are now ready to shadow score in production. The credit segment team has found a new source for employment data that can be useful to decisioning certain credit policies. The fraud team wants to pull in merchant foot traffic data. Making it easy to be able source and stream data into your systems to improve decisioning is a source of competitive advantage. My previous teams successfully moved legacy data pipelines over to the modern serverless AWS Glue data integration infrastructure and cut down timeframes from 2 months to 2 weeks. That is massive no matter how you look at it! Our customers loved us for that! It took us a while to design, build, test, and launch it but this proved to be a game changer. Data mobility and accessibility are organizational KPIs that you and your leaders should be measuring and improving, on an ongoing basis.
8. ML models data needs will keep rising. Organizations all around us are kicking the tires on data science and machine learning. During my time at Capital One, my teams supported a variety of fraud and credit ML use cases (both existing and new ones) with their data needs. If you look at a typical ML model lifecycle, it requires data at various stages: experimenting, training, testing, certifying, retraining, improving, and retesting. Building and running ML models are not one-and-done activities. As long as the model is “alive”, it will feed on a steady nutrition of data that you will be required to supply. There were times when we were caught off-guard with regards to the data needs of our DS partners. But we quickly realized that every type and piece of data within the organization, regardless of its origin and timing, could be used for a potential model use-case. So we started becoming a lot more intentional with regards to our own design and implementation approach. We moved from a reactive stance to a proactive stance, and significantly increased our engagement with our DS partners. This helped build transparency, trust, collaboration, and eventually speed of intent delivery.
9. Data instrumentation is critical for long-term analytics success. Instrumentation is the process of building/deploying tools that help you gauge your product performance. The scope of performance here covers both functional (i.e. Is the spend quality within the bounds of historical averages?) and non-functional (i.e. Is the transaction data making it to my operational and analytical data stores?). Every system produces data; yes, the mere fact that the data traversed through your universe means that you are now the producer of that data.
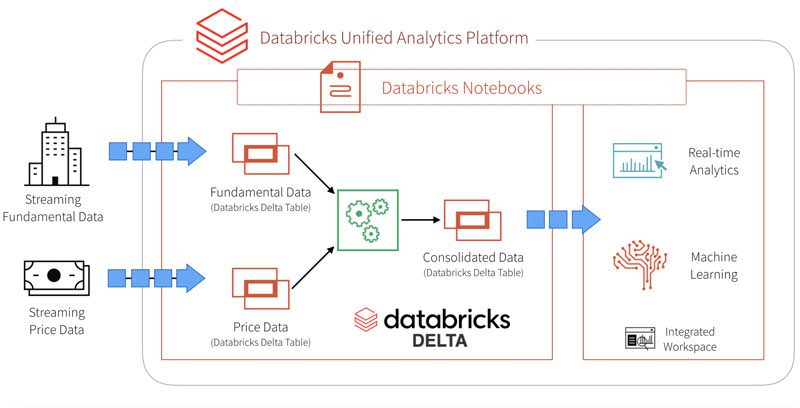
Data production, transformation, and decisioning is always in the service of a business need, purpose, objective and this means you must build tools to monitor its health and hygiene. Often teams think that most of these responsibilities lay with teams that are consuming or requesting the data, not the ones producing it. WRONG! As a data producer, you must take time to understand/document the data SLAs and guarantee that the data is meeting or exceeding those benchmarks. Organizational functions are all seamlessly tied to each other, so the performance and outputs of an upstream system impact those of the downstream system. Our analyst team successfully used Databricks and Snowflake to quickly build simple yet very effective tools to monitor daily decisioning and exhaust performance metrics. We also automated the analysis and distribution of the metrics to a large extent, and this resulted in a huge lift in performance outcomes, reduction in engineer involvement, and transparency of platform operations.
A data-driven organization is imperative for the future.
10. Your prod support teams need data literacy too. How gracefully does your show run when you are not around (non-core hours, vacation, holiday) is the simplest, unequivocal test of the quality of your system and processes. Typical organizations have production support teams (Tier 1or 2 support) that play the role of first responders. When there is a distress signal in a system dashboard or an outage message on a Slack channel, how well equipped is your prod support team to own and resolve the breakdown? Is there usual reaction to lookup the SME listed on a confluence page and wake them up in the middle of the night or weekend? Do they know where/how to look up the system support playbooks? Do they know how to tell a false positive from a true positive? Are the PagerDuty alerts on Slack also coded with a deep link to the support playbook? At this point, data related anomalies and breakdowns are an expected inconvenience. You must do an honest assessment of your prod support processes and metrics (Don’t tell me you have none!), and prioritize/rally the resources to make your operational processes well-managed and world-class. This too is a form of tech debt. Or else be ready to constantly have your engineering teams be sucked into prod support and take a hit on their intent velocity.
So there you have it, my 10 data lessons/learning from 2021. I know it was a long read but I hope some of these resonated with you.